Price reduction for PDF API
We are lowering our PDF API price to provide our customers with a more affordable option to process a large number of PDF documents. The price change is effective immediately: on June 1st, PDF API customers will be billed for May PDF usage at the new discounted price.
Old pricing:
$0.1/page (0-1K pages)
$0.05/page (1K+ pages)
$0.05/page (1K+ pages)
New pricing:
$0.025 / page (40K pages)
$0.01 / page (40K+ pages)
$0.01 / page (40K+ pages)
If you have a very large PDF collection (over one million pages) that you would like to digitize, please contact sales@mathpix.com so that we can give you a quote to buy PDF page credits at a discounted price.
Plain Markdown outputs from PDFs for your LLMs
We use Mathpix Markdown extensively because it is an expressive and feature-rich markup language for handling STEM documents that resolves many of the limitations of plain Markdown. However, modern LLMs are usually trained on plain Markdown and are not as knowledgeable about Mathpix Markdown which is a superset of Markdown. To that end, we now support plain
.md outputs in our API, in addition to Mathpix Markdown outputs .mmd:Tables, for instance, are represented in our plain Markdown outputs using standard Markdown syntax, e.g.
| Syntax | Description |
| ----------- | ----------- |
| Header | Title |
| Paragraph | Text |
instead of using the Mathpix Markdown syntax
\begin{tabular} … \end{tabular} (which is the same syntax used for LaTeX).Section headers for plain Markdown outputs use the more standard
# Section and ## Subsection.Also note that Markdown outputs also use dollar delimiters
$...$ and $ … $ for mathematical expressions by default instead of the \( … \) and \[ … \] delimiters we use by default for Mathpix Markdown outputs. We have noticed that this greatly enhances interoperability with ChatGPT.Faster PDF processing
We have decreased our average processing time per page by over 50%. We will continue to optimize PDF processing latency in the near future.
Basic support for multiple column images for v3/text endpoint
We have just introduced basic support for images with multiple columns in our image processing endpoint (v3/text, we already supported this for v3/pdfs). We will continue to improve our layout analysis capabilities for both our image processing endpoint, as well as our PDF processing endpoint, in the near future.
Improved chemical diagram recognition
Image to SMILES conversion overall has been significantly improved, and now includes support for stereochemistry and Markush structures.
Stereochemistry:
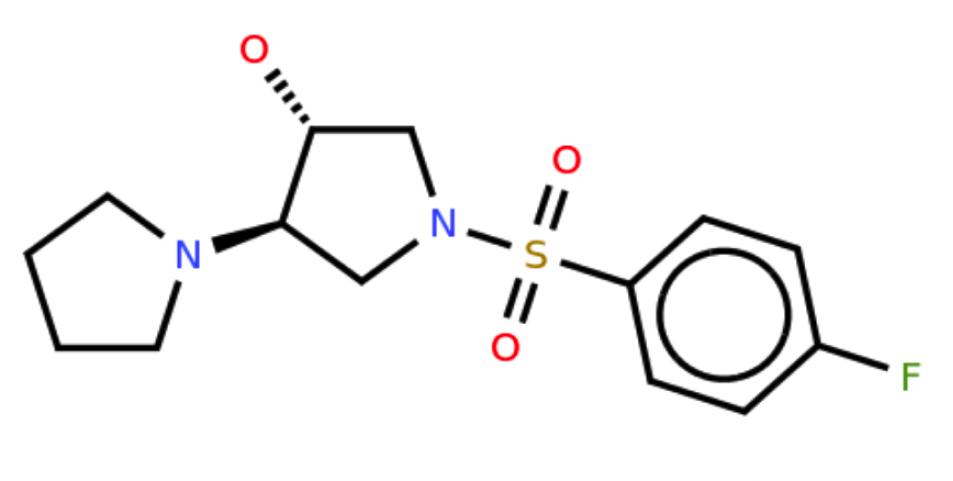
Generated SMILES:
O=S(=O)(c1ccc(F)cc1)N1C[C@@H](O)[C@H](N2CCCC2)C1Markush structures:
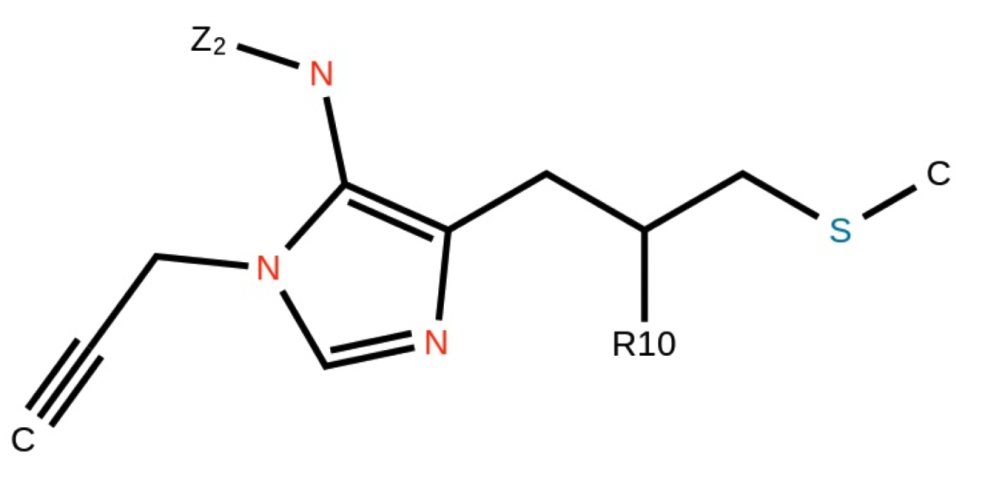
Generated SMILES:
[Z2]Nc1c(CC([R10])CSC)ncn1CC#C