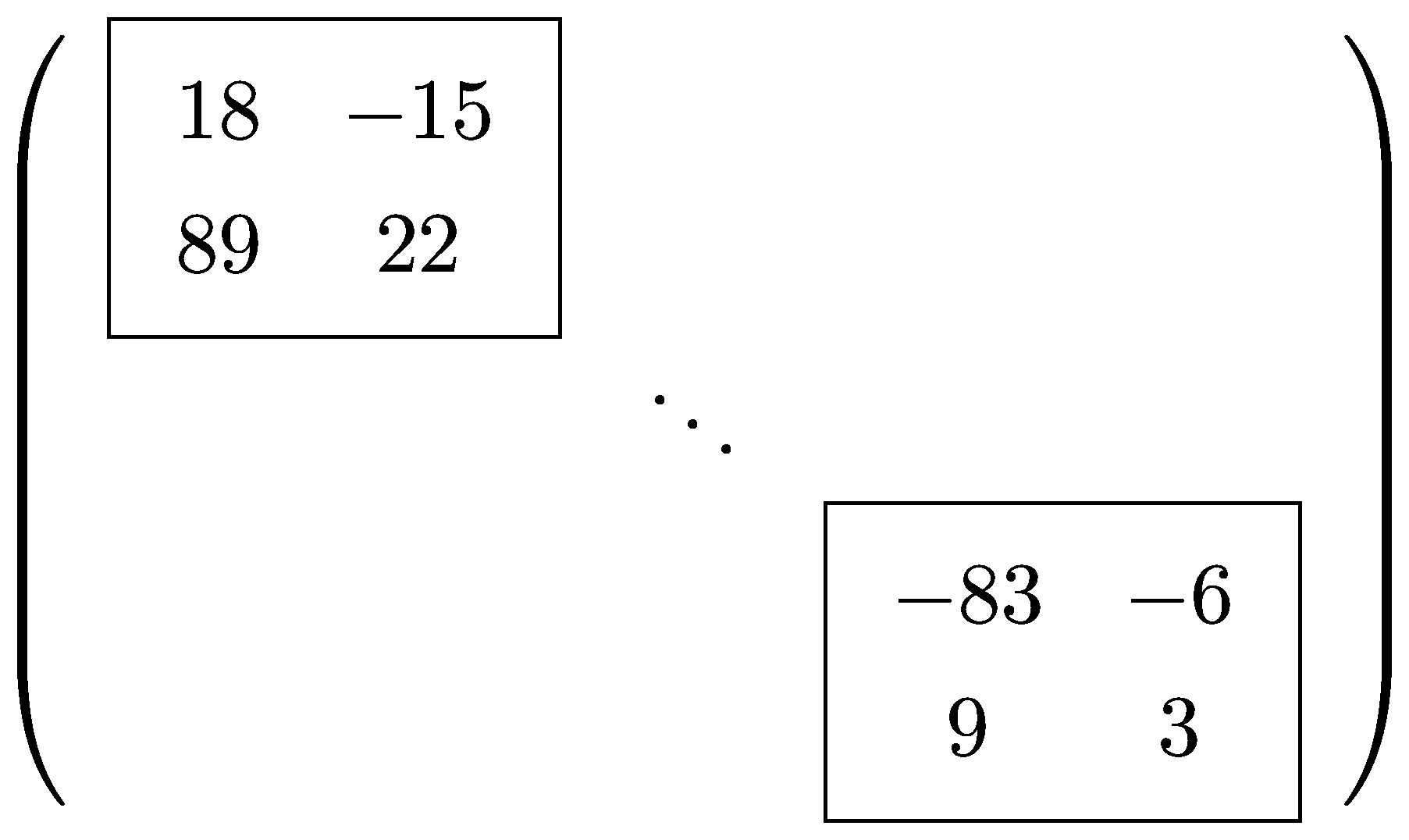
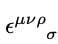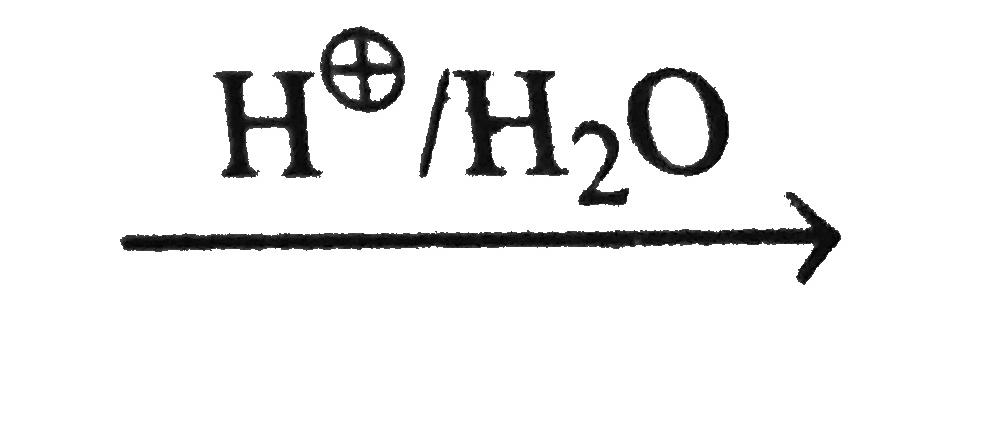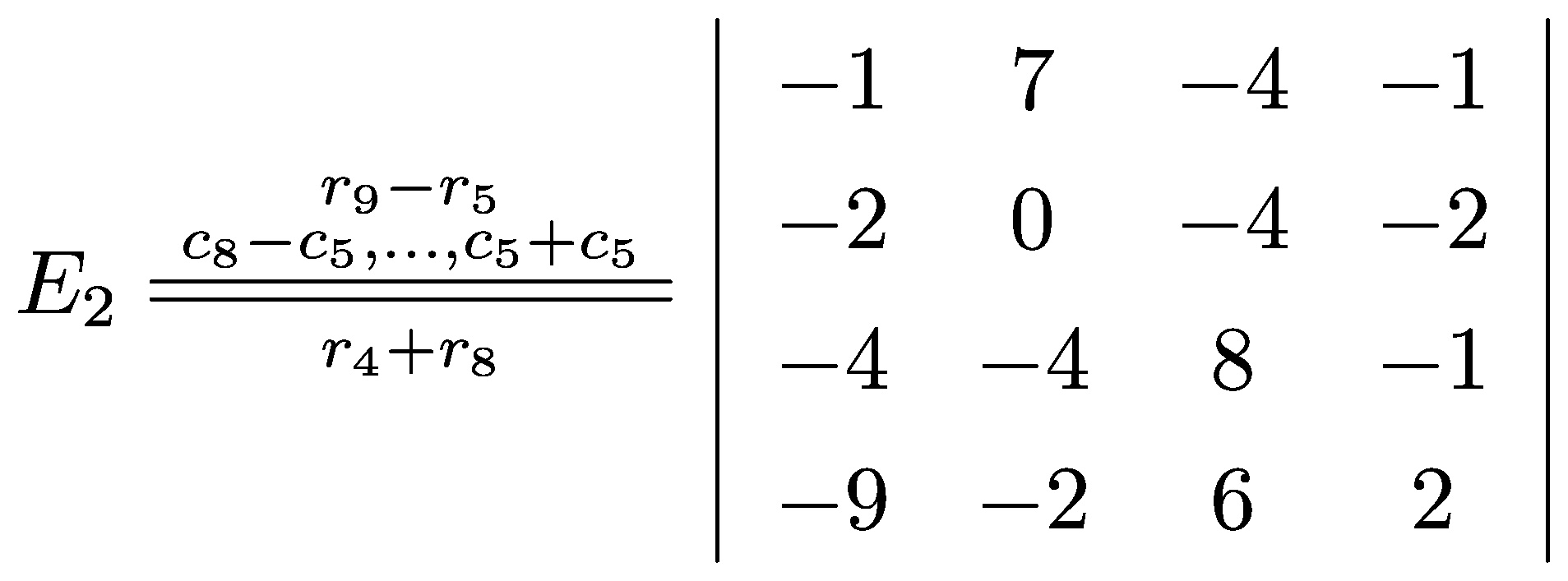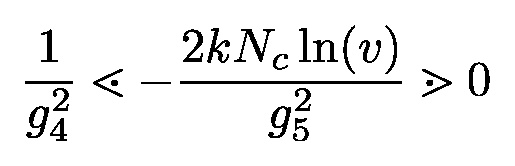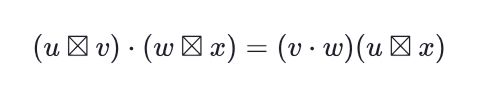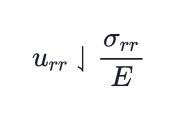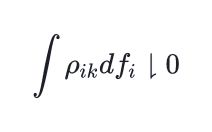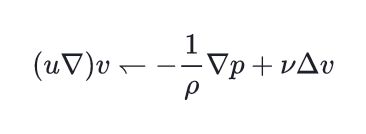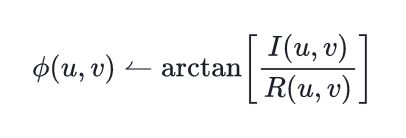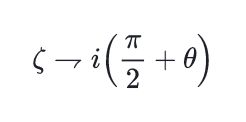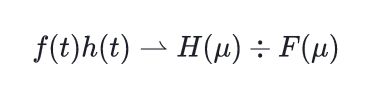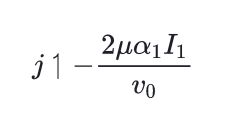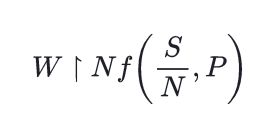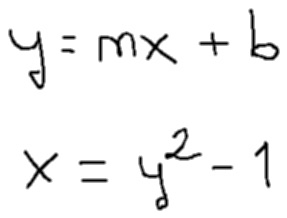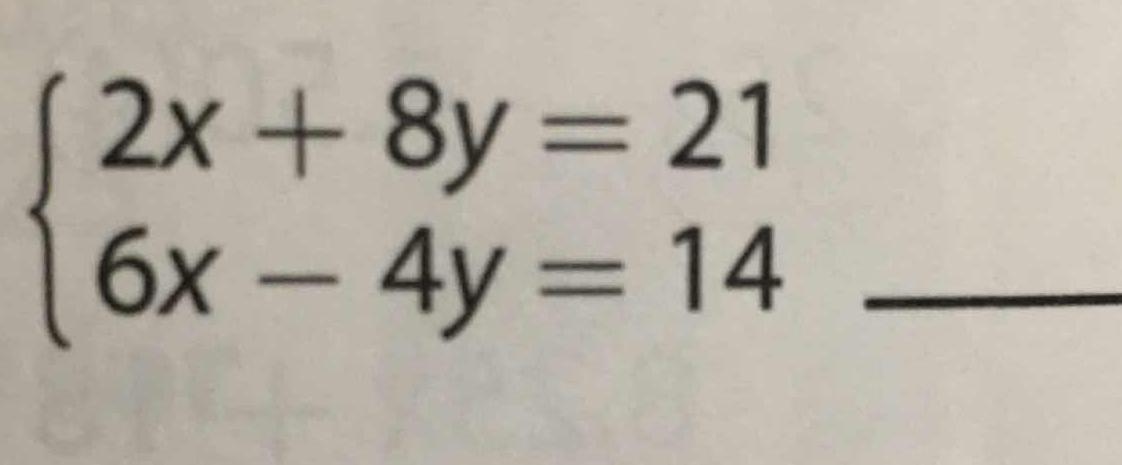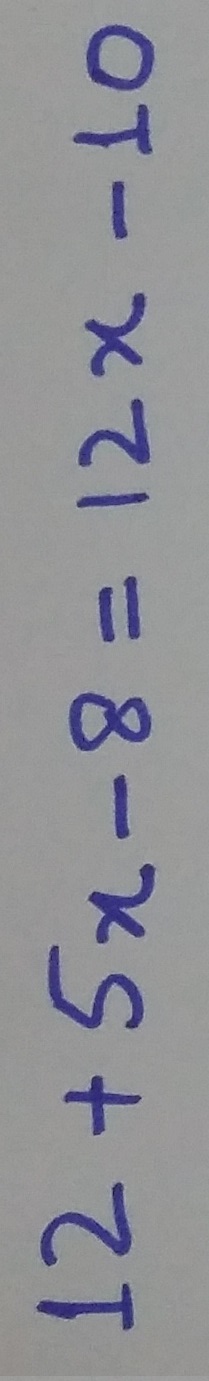Post-processing fixes for a very rare bugs related to code blocks rendering
June 26, 2025
Deployed new version SuperNet-103
General OCR accuracy improvements, with the additional focus on handwritten Japanese and handwritten Chinese
June 20, 2025
Deployed new version SuperNet-102i2
Improved recovery of network errors wrt. internal resources
May 16, 2025
Deployed new version SuperNet-102i1
Improved recovery of various CUDA errors, which were leading to internal error responses for unfortunate requests
May 8, 2025
Deployed new version SuperNet-102
General OCR recognition improvements; Chinese pause comma symbol 、 is now recognized properly, and not converted into regular full-width comma
May 6, 2025
Deployed new version SuperNet-101p3
Resolved a very rare table recognition-related corner cases that led to internal errors
May 5, 2025
Deployed new version SuperNet-101p2 (v3/pdf)
Improved processing of equation numbers (relevant when "include_equation_tags": true is specified)
April 28, 2025
Deployed new version SuperNet-101p1 (v3/pdf)
HTML conversion improvements.
April 23, 2025
Deployed new version: SuperNet-101
Improvements in the quality of predictions, minor performance improvements
April 18, 2025
Deployed new version SuperNet-100p2 (v3/pdf)
Markdown conversion improvements:
Added the max_character_per_line parameter.
The max_character_per_line parameter can accept a numerical value and should not be less than 10.
When this parameter is set, the Markdown content will be split such that no line exceeds the specified character limit.
April 17, 2025
Deployed new version: SuperNet-100p1
Post-processing fix that prevents internal error in case of a very specific invalid table structure prediction
April 16, 2025
Deployed new version: SuperNet-100
Overall image parsing improvements, and additional features:
we are adding id, parent_id, children_ids, type, subtype, conversion_output, and text_display to lines.json line format (v3/pdf*)
lines.json will now contain full hierarchy of page elements, even when there is no text directly associated with it (for example table of contents, text column, etc.)
text field of lines.json will be an empty string in cases when no search text can be associated with page element in order not to break the existing client code
all other fields that were added will be included only if there is a value; for example if the page element does not have any children there will be no key children_ids for that element in the JSON
lines.mmd.json is left unchanged in order not to break the client code, but we encourage you to switch to using richer lines.json format
we are adding id, parent_id, and children_ids to line data output format (v3/text); if there is no parent, or no children appropriate keys will be omitted from the output
returning in-diagram text as a part of line data (v3/text) and lines.json data (v3/pdf*)
needs to activated with request option "include_diagram_text": true
this feature is basic, and regular accuracy improvements are expected over the next period
parent_id/children_ids can be used to associate particular text with the correct diagram
improved code/pseudocode recognition
improved handling of rotated images and rotated PDF pages
improved recognition of +/-90 degrees rotated table cells
initial support for recognition of diagonally split table cells
Additional changes and deprecation:
we are deprecating triangle shape associated with "include_geometry_data"; diagram labels will be returned in unchanged way
there is chance of increased latency for very large tables due to improved algorithm being more compute intensive
April 15, 2025
Deployed new version RSK-P127p12i1 (v3/pdf)
Conversions improvements:
Added supporting for LaTeX commands \diagbox, \slashbox, and \backslashbox to handle split table cells properly.
April 1, 2025
Deployed new versions: RSK-M136p5 (v3/text) and RSK-P127p11 (v3/pdf*)
Fixing post-processing of binoms that contain text.
March 31, 2025
Deployed new version RSK-P127p10 (v3/pdf)
Conversion improvements
Disallowed the use of <iframe> tags in HTML for security reasons
March 26, 2025
Deployed new version RSK-P127p9 (v3/pdf)
The GET /v3/pdf/{pdf_id}.{ext} endpoint now has the ability to return PDFs:
GET /v3/pdf/{pdf_id}.pdf - returns PDF (with HTML)
GET /v3/pdf/{pdf_id}.latex.pdf - returns PDF (with Latex)
March 6, 2025
Deployed new version RSK-P127p8 (v3/pdf)
DOCX conversion improvements:
Added custom_css option for applying inline styles.support.
Added text_color and background_color option to set common document colors.
Added margin option to specify the margin size in px.
Fixed issue with block code inside markdown lists.
February 26, 2025
Deployed new versions: RSK-M136p4 (v3/text) and RSK-P127p7 (v3/pdf*)
Enabling association of equation tags with non-centered math equations.
Improving parsing of equation numbers.
For example, when "include_equation_tags": true, we will now recognize this part of the image/PDF page:
as (please note equation tags for each equation):
Finally, $\Gamma_{l}, \Delta_{q}, \Delta_{r}$ and $\Delta_{t}$ are the result of the surface integrations of the modes:
$$
\begin{equation*}
\Gamma_{l}=\iint_{S} W_{l}^{2}(x, z) d x d z \tag{36}
\end{equation*}
$$
$$
\begin{equation*}
\Delta_{q}=\iint_{S}\left(\Phi_{q}^{I}\right)^{2}(x, z) d x d z \tag{37}
\end{equation*}
$$
$$
\begin{equation*}
\Delta_{r}=\iint_{S_{w}}\left(\Phi_{r}^{I I}\right)^{2}(x, z) d x d z \tag{38}
\end{equation*}
$$
$$
\begin{equation*}
\Delta_{t}=\iint_{S}\left(\Phi_{t}^{I I I}\right)^{2}(x, z) d x d z \tag{39}
\end{equation*}
$$
By solving this system of equations simultaneously, the unknown sets of coefficients $A_{k}, B_{p}^{-}$and $B_{p}^{+}$can be obtained. Subsequently, the
which renders as:
February 17, 2025
Deployed new version RSK-P127p6 (v3/pdf)
PDF (with HTML), HTML, DOCX conversions improvements
Added footnote_compact_refs option to hide repeat index for markdown footnote
February 5, 2025
Deployed new version RSK-P127p5 (v3/pdf)
Added confidence and confidence_rate to PDF line data for lines.json and lines.mmd.json
February 4, 2025
Deployed new version RSK-P127p4 (v3/pdf)
PDF (with HTML) conversion improvements
Fixed Gujarati text in exported PDF
January 27, 2025
Deployed new version RSK-M136p3 (v3/text)
Fixes pre-processing bug which resulted in no content being returned for a very rare class of images
January 24, 2025
Deployed new version RSK-P127p3 (v3/pdf)
Latex conversion improvements
Fixed Hindi and Gujarati text in exported latex where it was not showing in Overleaf/TexStudio
In XeLaTeX mode, the use of macros has been added to use system fonts if the specified font is not found in the system.
January 22, 2025
Deployed new versions: RSK-M136p2 (v3/text) and RSK-P127p2 (v3/pdf*)
Using halfwidth hyphen and space after for Markdown lists that contain mostly Chinese text
Previously it could happen that fullwidth hyphen and no space was used which prevents correct rendering of Markdown lists.
January 15, 2025
Deployed new version RSK-P127p1 (v3/pdf)
Adds support to convert epub, docx, pptx, and other ebook and document file formats
January 13, 2025
Deployed new version RSK-M136p1 (v3/text)
Preventing internal errors for invalid math delimiters request options; error towards returning content
December 30, 2024
Deployed new versions: RSK-M136 (v3/text) and RSK-P127 (v3/pdf*)
OCR engine improvements, new API parameter fullwidth_punctuation which controls which Unicode symbols are used for punctuation (for details, please see https://docs.mathpix.com/#request-parameters)
December 26, 2024
Deployed new versions: RSK-M135p3 (v3/text) and RSK-P126p4 (v3/pdf*)
Quoted text is now formatted as Markdown quotes
For the part of PDF page like this one:
the centered text will get formatted as:
Skovhus and Thomsen (2020) have previously articulated a pertinent concern in their study on taster programmes. The concern is that:
> When students, maybe with good reason, perceive career guidance activities as intended to help them make a choice, many of those who have already decided on a particular upper secondary programme find them a waste of time ... The reason for this is that the taster programmes, with few exceptions, are detached from the curriculum of the various compulsory school subjects and, as such, not integrated in classroom teaching. The activities become isolated, one-off events with no systematic preparation beforehand or facilitated reflection afterwards. (p. 260-261)
They advocate for a fundamental shift in the orientation of taster programme activities and school-based career guidance in general. Their argument is rooted in the need to redirect the focus from mere educational choices towards a more comprehensive and holistic career learning approach that fosters young individuals' exploration of education and career possibilities. This
which renders as:
December 24, 2024
Deployed new version RSK-P126p3 (v3/pdf*)
Conversion improvements
December 24, 2024
Deployed new version RSK-M135p2 (v3/text)
Fixing export of triangle vertex coordinates when "include_geometry_data": true is specified in the request
December 23, 2024
Update PDF streaming API so that ordering is enforced
Deployed new versions: RSK-M135 (v3/text) and RSK-P126 (v3/pdf*)
Improve page layout parsing
Deployed new versions: RSK-M135p1 (v3/text) and RSK-P126p2 (v3/pdf*)
Fixes minor issues with table of contents
December 19, 2024
Deployed new versions: RSK-M134p13 (v3/text) and RSK-P125p8 (v3/pdf*)
Fixes rare internal error
December 18, 2024
Deployed new version RSK-P125p7 (v3/pdf*)
Making sure image crops (diagrams, etc.) are within PDF page boundaries
December 16, 2024
Deployed new PDF API version RSK-P125p5 (v3/pdf) with new GET endpoint api.mathpix.com/v3/pdf/{pdf_id}/stream with streaming enabled; see http://docs.mathpix.com/?python#stream-pdf-pages for more information.
Deployed new image API versions: RSK-M134p11 (v3/text) and RSK-P125p5 (v3/pdf*) that fixes a rare bug.
December 10, 2024
Deployed new versions: RSK-M134p10 (v3/text) and RSK-P125p4 (v3/pdf*)
Fixes a very rare bug in spelling correction which was leading to internal error response
December 3, 2024
Deployed new versions: RSK-M134p9 (v3/text) and RSK-P125p3 (v3/pdf*)
Not escaping table cell delimiter (& symbol) inside tables when it happens inside sub-environment (e.g. \begin{aligned}...\end{aligned} inside table cell)
November 26, 2024
Deployed new versions: RSK-M134p8 (v3/text) and RSK-P125p2 (v3/pdf*)
Minor bugfix for gathered math environment
November 26, 2024
Deployed new versions: RSK-M134p7 (v3/text) and RSK-P125p1 (v3/pdf*)
Fixing a rare case of nested align* environments when "include_equation_tags": true
November 25, 2024
Deployed new version RSK-M125 (v3/pdf*)
Improved detection of abstracts, titles, and other semantic text categories.
One notable change is that we now allow for multiple \title{} elements in the single PDF. Here is a screenshot of an example page that has two titles:
November 20, 2024
Deployed new versions RSK-P124p7 (v3/pdf*)
Conversion improvements
November 19, 2024
Deployed new versions: RSK-M134p6 (v3/text) and RSK-P124p6 (v3/pdf*)
Post-processing improvements for tables with several multicolumn cells inside a single row
November 15, 2024
Deployed new versions: RSK-M134p5 (v3/text) and RSK-P124p5 (v3/pdf*)
Several post-processing improvements
November 7, 2024
Deployed new versions: RSK-M134p4 (v3/text) and RSK-P124p4 (v3/pdf*)
Preventing multicolumn overflow, respecting the total number of table columns
November 4, 2024
Deployed new version RSK-P124p3 (v3/pdf*)
Conversion improvements
November 3, 2024
Deployed new version RSK-M134p3 (v3/text)
Returning Content not found error in some edge cases that previously resulted in internal error
November 1, 2024
Deployed new versions: RSK-M134p2 (v3/text) and RSK-P124p2 (v3/pdf*)
Fixes for rare bugs that occurred during table segmentation
Better support for custom math display delimiters like ["\\begin{equation*}\n", "\n\\end{equation*}"] with equation tags
Most common choices like $$ and \[, \] work well in cases like:
To prevent bad outcomes, we’re now keeping the original math environment when necessary, in order to support equation tags properly. We omit equation* environment and produce the following output:
\begin{align*}
x &= y^2 \tag{1}\\
&= 16 \tag{2}
\end{align*}
October 28, 2024
Deployed new versions: RSK-M134p1 (v3/text) and RSK-P124p1 (v3/pdf*)
Minor pre-processing changes
October 22, 2024
Deployed new version RSK-P124 (v3/pdf*)
Added support for rotated parts of PDF page(s) (e.g. 90 degrees rotated table)
Previously, v3/pdf wasn’t handling PDF pages with rotated content properly, leading to parts of page being digitized as an image link instead of recognized content. This has changed with current version.
For example, a PDF page like this one:
is now processed in v3/pdf into the following MMD:
Table 1 Common Q System Qualified Components
\begin{tabular}{|c|c|c|c|}
\hline Item & Component & \begin{tabular}{l}
Product Revision \\
(Up to this revision reviewed for this SE)
\end{tabular} & Description \\
\hline AC160 Hardware Modules & & & \\
\hline 1 & Al620 & A & S600 Analog Input Module \\
\hline 2 & Al685 & G & S600 Analog Input Module \\
\hline 3 & Al687 & C & S600 Analog Input Module \\
\hline 4 & Al688 & A & S600 Analog Input Module \\
\hline 5 & A0610 & A & S600 Analog Output Module \\
\hline 6 & A0650 & A & S600 Analog Output Module \\
\hline 7 & CI527W & C & Communications Interface Module \\
\hline 8 & Cl631 & F & Communications Interface Module \\
\hline 9 & DI620 & A & S600 Digital Input Module \\
\hline 10 & DI621 & A & S600 Digital Input Module \\
\hline 11 & D0620 & C & \begin{tabular}{l}
S600 Digital Output \\
Module
\end{tabular} \\
\hline 12 & D0625 & A & \begin{tabular}{l}
S600 Digital Output \\
Module
\end{tabular} \\
\hline 13 & D0630 & A & \begin{tabular}{l}
S600 Digital Output \\
Module
\end{tabular} \\
\hline
\end{tabular}
which renders as:
October 17, 2024
Deployed new versions: RSK-M134 (v3/text) and RSK-P123 (v3/pdf*)
OCR engine general accuracy improvements
October 8, 2024
Deployed new versions RSK-P122p2 (v3/pdf*)
Conversion improvements
October 6, 2024
Deployed new versions: RSK-M133p1 (v3/text) and RSK-P122p1 (v3/pdf*)
Improving post-processing robustness in extremely rare edge case
October 3, 2024
Deployed new versions: RSK-M133 (v3/text) and RSK-P122 (v3/pdf*)
Table recognition improvements, with accent on math-heavy tables
For example, complex tables like this:
are now successfully recognized, and the output returned renders as:
Corresponding MMD:
\begin{tabular}{|c|c|c|c|}
\hline Question & Scheme & Marks & Aos \\
\hline \multirow[t]{5}{*}{(a)} & A complete method to use the scalar product of the direction vectors and the angle \( 120^{\circ} \) to form an equation in \( a \)
\[
\frac{\left(\begin{array}{l}
2 \\
a \\
0
\end{array}\right) \cdot\left(\begin{array}{r}
0 \\
1 \\
-1
\end{array}\right)}{\sqrt{2^{2}+a^{2}} \sqrt{1^{2}+(-1)^{2}}}=\cos 120
\] & M1 & \( 3.1 b \) \\
\hline & \[
\frac{a}{\sqrt{4+a^{2}} \sqrt{2}}=-\frac{1}{2}
\] & A1 & 1.1 b \\
\hline & \( 2 a=-\sqrt{4+a^{2}} \sqrt{2} \Rightarrow 4 a^{2}=8+2 a^{2} \Rightarrow a^{2}=4 \Rightarrow a=\ldots \) & M1 & \( 1.1 b \) \\
\hline & \( a=-2 \) & A1 & 2.2 a \\
\hline & & (4) & \\
\hline \multirow[t]{6}{*}{(b)} & \[
\begin{align*}
\text { Any two of } \mathbf{i}: & -1+2 \lambda=4 \\
& \mathbf{j}: 5+\text { 'their }-2 ' \lambda=-1+\mu \tag{2}\\
& \mathbf{k}: \quad 2=3-\mu \tag{3}
\end{align*}
\] & M1 & 3.4 \\
\hline & Solves the equations to find a value of \( \lambda\left\{=\frac{5}{2}\right\} \) and \( \mu\{=1\} \) & M1 & 1.1 b \\
\hline & \[
r_{1}=\left(\begin{array}{c}
-1 \\
5 \\
2
\end{array}\right)+\frac{5}{2}\left(\begin{array}{c}
2 \\
\text { 'their }-2^{\prime} \\
0
\end{array}\right) \text { or } r_{2}=\left(\begin{array}{c}
4 \\
-1 \\
3
\end{array}\right)+1\left(\begin{array}{c}
0 \\
1 \\
-1
\end{array}\right)
\] & dM1 & 1.1 b \\
\hline & \[
(4,0,2) \text { or }\left(\begin{array}{l}
4 \\
0 \\
2
\end{array}\right)
\] & A1 & 1.1 b \\
\hline & \begin{tabular}{l}
Checks the third equation e.g.
\[
\begin{array}{ll}
\lambda=\frac{5}{2}: \mathrm{L} & \mathrm{HS}=5-2 \lambda=5-5=0 \\
\mu=1: \mathrm{R} & \mathrm{HS}=-1+\mu=-1+1=0
\end{array}
\] \\
therefore common point/intersect/consistent/tick or substitutes the values of \( \lambda \) and \( \mu \) into the relevant lines and achieves the same coordinate
\end{tabular} & B1 & 2.1 \\
\hline & & (5) & \\
\hline
\end{tabular}
October 2, 2024
Deployed new versions: RSK-M132p13 (v3/text) and RSK-P121p7 (v3/pdf*)
Post-processing improvements
September 30, 2024
Deployed new versions RSK-P121p6 (v3/pdf*)
Added parameter include_chemistry_as_image to return chemistry as an image crop with SMILES content in the alt-text
September 23, 2024
Deployed new versions RSK-P121p5 (v3/pdf*)
Conversion improvements
September 23, 2024
Deployed new versions: RSK-M132p12 (v3/text) and RSK-P121p4 (v3/pdf*)
Post-processing improvements
September 20, 2024
Deployed new versions: RSK-M132p11i1 (v3/text) and RSK-P121i1p3 (v3/pdf*)
Choosing table segmentation as table OCR algorithm more frequently
September 18, 2024
Deployed new versions RSK-M132p10i1 (v3/text) and RSK-P121i1p2 (v3/pdf)
Fixes double output in latex_styled format in some cases
Post-processing changes (v3/pdf)
September 12, 2024
Deployed new version RSK-P121i1p1 (v3/pdf)
Fixing very rare cases where diagrams get post processed incorrectly
September 10, 2024
Deployed new version RSK-P121 (v3/pdf)
Model updates
September 6, 2024
Deployed new version RSK-M132p9 (v3/text)
Prevent generating image link in the output for charts in certain cases
September 5, 2024
Deployed new version RSK-P120 (v3/pdf)
Model updates
September 2, 2024
Deployed new versions: RSK-M132p8 (v3/text) and RSK-P119p1 (v3/pdf*)
Corrects wrong equation ordering in the output which was happening in certain cases
September 1, 2024
Deployed new version RSK-P119 (v3/pdf)
Model re-trained on more data
August 30, 2024
Deployed new versions: RSK-M132p7 (v3/text) and RSK-P118p10 (v3/pdf*)
Updated MathJax@3.2.2
Improved Asciimath outputs. An extra space is no longer added after the function name and before the opening bracket (e.g., arctan((1)/(x)) instead of arctan ((1)/(x)))
August 29, 2024
Deployed new versions: RSK-M132p6 (v3/text) and RSK-P118p9 (v3/pdf)
Post-processing fixes.
August 26, 2024
Renamed OCR API to Convert API
August 23, 2024
Deployed new version RSK-P118p8 (v3/pdf)
Code blocks now have double newline separation when multiple pages are joined which is more consistent (it used to be a single newline).
Deployed new versions: RSK-M132p5 (v3/text) and RSK-P118p7 (v3/pdf)
Post-processing improvements for cases when diagrams have significant intersections with text lines.
August 21, 2024
Deployed new versions: RSK-M132p4 (v3/text) and RSK-P118p6 (v3/pdf)
Fixes post-processing issues related to code recognition and footnote text.
Fixes some internal errors.
Single line footnote text was sometimes left unclosed, without a matching closing }. For example, response from the API would return something like:
\footnotetext{
* My single line footnote
This deployment corrects it to:
\footnotetext{
* My single line footnote
}
In some ambiguous cases, we have been omitting the closing triple back ticks which are MMD code delimiters. That has lead to improper rendering in those cases. Most of these situations, if not all, should be fixed by this deployment.
August 20, 2024
Deployed new versions: RSK-M132p3 (v3/text) and RSK-P118p5 (v3/pdf)
Improved processing of tables with complex content inside cells.
This deployment improves on table OCR when tables have cells with complex content. Here is an example of a very simple table with a complex cell just to illustrate the type of data that these changes affect positively:
First cell of the second row has 3 lines of text and an equation. The table gets processed into MMD like this one:
\begin{tabular}{|c|c|c|}
\hline First column & Second column & Third column \\
\hline \begin{tabular}{l}
This cell has multiple lines \\
which enables testing tableocr properly. \\
Here goes the equation: \\
\( L=-\frac{1}{N} \sum_{i=0}^{N-1} y_{i} \log \left(\hat{y}_{i}\right) \)
\end{tabular} & Normal cell & Normal cell \\
\hline
\end{tabular}
which renders as:
August 16, 2024
Deployed new version: RSK-M132p2 (v3/text)
Adds back missing line data formats (data and html)
Resolves some cases of incorrect error reporting for v3/latex endpoint
August 15, 2024
Deployed new versions: RSK-M132p1 (v3/text) and RSK-P118p4 (v3/pdf)
Enables "include_equation_tags": boolean boolean option for v3/text (default is false).
Post-processing improvements.
August 14, 2024
Deployed new version: RSK-P118p3 (v3/pdf)
Fixes diagram post-processing issues.
Adds request option include_smiles for digitizing chemistry diagrams (true by default). When false chemistry diagram is preserved as an image.
August 10, 2024
Deployed new version: RSK-P118p2 (v3/pdf)
Fixes rare post-processing issues related to equations processing.
August 6, 2024
Deployed new version: RSK-P118p1 (v3/pdf)
Fixes post-processing issues related to tables processing.
July 29, 2024
Deployed new versions: RSK-M132 (v3/text) and RSK-P118 (v3/pdf)
OCR engine updates
July 26, 2024
Deployed new version: RSK-P117p5i4 (v3/pdf)
Correctly including equation tags in some edge cases.
July 10, 2024
Deployed new versions: RSK-M131p6i3 (v3/text) and RSK-P117p3i2 (v3/pdf)
We now move “1text1 \mathrm { text }” to “1text1 text” wherever possible. We also have an API option math_fonts_default_to_math to disable this behavior.
June 22, 2024
Deployed new version RSK-M131p6i2 (v3/text)
Fixes internal errors in v3/text when invalid format is specified in "formats" request argument. Instead of internal error we now return results for all supported formats the were specified in the request, and we ignore the unsupported ones. For details on supported formats see here.
June 19, 2024
Deployed new version RSK-M131p4i1 (v3/text)
Fixes parsing of chemicals in wrongly rotated images when autorotation is detected correctly.
June 12, 2024
Deployed new version RSK-M131p3i1 (v3/text)
Fixes wrong items in detection map output, namely contains_chart, and contains_graph
June 9, 2024
Deployed new version RSK-P117p1 (v3/pdf)
Fixes handling of unrecognized tables in post-processing.
June 7, 2024
Deployed new versions RSK-P117 (v3/pdf)
This update fixes problems caused by rotated side text detection, improves source code recognition, and recognition of very small lines (e.g. single character line {)
May 31, 2024
Deployed new versions RSK-P116p2i1 (v3/pdf)
Given $ as inline math delimiter, form fields are recognized without surrounding spaces as $\qquad$ instead of $ \qquad $ because the former has rendering issues
May 30, 2024
Deployed new versions: RSK-M131p2i1 (v3/text) and RSK-P116p1i1 (v3/pdf)
Post-processing fixes that eliminate several very rare internal errors. We now either return requested content, or no content if there is nothing in the image.
May 27, 2024
Deployed new versions: RSK-M131 (v3/text) and RSK-P116 (v3/pdf)
Improvements of source code recognition; support for non-English languages in source code
For example, given an image like this:
returned response now includes correctly recognized Chinese ideographs:
```
def test_function():
# 测试数字之和
sum: int = 0
for i in range(1, 11):
sum += i
assert sum == 55
```
Requests that specify "include_line_data": true and contain an image such as:
will receive line data as:
[{"type":"text","cnt":[[29,29],[29,0],[368,0],[368,29]],"included":true,"is_printed":true,"is_handwritten":false,"text":"What is the area of the trapezoid?","after_hyphen":false,"confidence":1.0,"confidence_rate":1.0},{"type":"chart","cnt":[[303,331],[303,62],[681,62],[681,331]],"included":false,"is_printed":true,"is_handwritten":false,"subtype":"analytical","error_id":"image_not_supported"}]
which has an item with "type": "chart" and "subtype": "analytical".
May 15, 2024
Deployed new version: RSK-P115 (v3/pdf)
Improved handling of large capital letters at the beginning of paragraphs (see below)
For cases like this one, where the paragraph starts with a very large letter:
we now return correctly recognized text as:
There is now a substantial literature that connects religion and ...rest of text...
with a focus on starting T being handled properly.
May 9, 2024
Deployed new versions: RSK-M129p2i1 (v3/text) and RSK-P114p2i1 (v3/pdf)
Performance improvements:
Faster response times across all endpoints.
Large PDFs should now go from loaded to split much faster (splitting time).
May 1, 2024
Deployed new versions: RSK-M129p1 (v3/text) and RSK-P114p1 (v3/pdf)
Post-processing updates for source code, among others:
\rightarrow to ->
\Rightarrow to =>
April 30, 2024
Deployed new versions: RSK-M129 (v3/text) and RSK-P114 (v3/pdf)
Update improves on handwritten Japanese and source code recognition
This update brings initial support for correct source code recognition from images. For example, for an image with source code listing like the following:
Mathpix now returns:
By combining multimethods and packages, we can simplify the abstract syntax tree example by bundling the visitation methods for each tree operation in a package.
```
object TypeChecker {
public:
void Visit(AssignmentNode & n) {
// ...
Visit (n.LHS ());
Visit (n.RHS ());
// ...
}
void Visit(VariableRefNode & n);
// ...
};
object CodeGenerator {
public:
void Visit(AssignmentNode & n);
void Visit(VariableRefNode & n);
// ...
};
Node & root = // ...
TypeChecker.Visit(root);
CodeGenerator.Visit(root);
```
which gets renders as:
Similarly, pseudocodes are also wrapped in three back ticks, while Latex with math notation is output. Note, this format for pseudocodes is likely to change in the future.
For pseudocode like the following image:
the output returned looks like:
```
Algorithm 3 An algorithm to divide a given size budget among subexpressions ${ }^{9}$
func Divide ( $a$ : Arity, $q$ : Size, $l$ : Op. Level, $j$ : Expr. Level, $\alpha$ : Accumulated Args.)
- Requires: $1 \leq a \leq q \wedge l \leq j$
if $a=1$ then
if $l=j \vee \exists\langle x, y\rangle \in \alpha: x=j$ then return $\{(1, q) \diamond \alpha, \ldots,(j, q) \diamond \alpha\}$
return $\{(j, q) \diamond \alpha\}$
$L=\{\}$
for $u \leftarrow 1$ to $j$ do
for $v \leftarrow 1$ to $(q-a+1)$ do
$L \leftarrow L \cup \operatorname{DIVIDE}(a-1, q-v, l, j,(u, v) \diamond \alpha)$
return $L$
```
If one wants to render recognized pseudocode, it is recommended to remove back ticks and replace indents of 4 spaces with $\quad$ . After these transformations the result is:
While Mathpix used to return links of image crop for source code and pseudocodes v3/pdf, that behavior is now changed and v3/pdf now returns MMD outputs as described in this changelog.
April 27, 2024
Deployed new versions: RSK-M128p3 (v3/text) and RSK-P113i1p1 (v3/pdf)
We now transform \begin{array}{l}{...x...}\\{...y...}\end{array} to \binom{...x...}{...y...}.
April 18, 2024
Deployed a new version: RSK-M128p2 (v3/text).
Minor post-processing fixes.
Deployed new version: RSK-P112 (v3/pdf*)
Initial support for detection of in-text placeholders to be filled in (form_field).
Algorithm updated with more data.
April 4, 2024
Deployed new version RSK-M128 (v3/text)
Improved source code and pseudo code indentation
source code is enclosed with triple backticks
Support for detection of in-text placeholders to be filled in (form_field)
placeholder underscores, dots, and dashes are output as \( \\qquad \)
placeholder boxes are output as \(\square\)
March 26, 2024
Deployed new version: RSK-P111p6i2 (v3/pdf*)
Improved export to DOCX: added flattening of nested text tables if the nested table is just one column with several rows.
March 15, 2024
Deployed new version: RSK-P111p5i2 (v3/pdf*)
MMD to PDF-LaTeX conversion improvements
Added additional fonts to support a broader range of scripts.
Expanded language detection capabilities to accurately and more reliably handle texts.
Language detection extended to include Thai, Tamil, Hebrew, Hindi, and Bengali.
Automatically use XeLaTeX for documents containing non-Latin, Greek, Cyrillic (LGC) scripts, ensuring better
rendering of multilingual texts.
Standardized font usage to the Noto family for non-LGC scripts, providing consistency and extensive script support
across documents.
MMD to LaTeX conversions and the tex.zip extension’s output may now include code requiring XeLaTeX for proper rendering of non-LGC texts. It’s notable that only Note to PDF-LaTeX allows for specific font selection. For MMD to LaTeX and the output from the tex.zip extension, conversions standardize on CMU Serif and Noto Serif for non-LGC scripts.
March 13, 2024
Deployed a new version: RSK-M127p5i1 (v3/text).
Fixed incorrect duplication of the “caret” in Asciimath outputs (e.g., 100(1.03)^2t=5000 instead of 100(1.03)^(^^)2t=5000).
Deployed new version: RSK-P111p4i2 (v3/pdf*)
Improved export to DOCX: added the ability to automatically detect the language for the entire document.
February 29, 2024
Deployed new versions: RSK-M127p4i1 (v3/text and v3/latex) and RSK-P111p3i2 (v3/pdf*)
General efficiency improvements.
February 26, 2024
Deployed new version: RSK-P111p3i1 (v3/pdf*)
Improved export to LaTeX (tex.zip): we now use double backslashes (\\) for line breaks in the Table of Contents and various sections without starting a new paragraph in text mode.
February 22, 2024
Deployed a new version: RSK-M127p3 (v3/text).
Fixed incorrect grouping of fractional function arguments in Asciimath outputs, fractional function arguments are now properly contained within functions by being wrapped in parentheses (e.g., sec ((5theta)/(4))=2 instead of sec (5theta)/(4)=2 and log ((x)/(y^(5))) instead of log (x)/(y^(5))).
February 16, 2024
Deployed a new version: RSK-M127p3 (v3/text and v3/latex).
We now validate the region parameter and return appropriate error messages.
February 6, 2024
Deployed new version: RSK-P111p2 (v3/pdf*)
Added new API option "include_equation_tags": boolean
We’re excited to announce an enhancement to our v3/pdf* endpoints: the ability to include recognized equation numbers directly within the MMD output. Previously, equation numbers were only accessible through the lines.json output format, serving primarily for search purposes without visibility in the main MMD content.
With the new "include_equation_tags": true parameter, our system now integrates equation numbers seamlessly into the MMD output, utilizing the \tag element for clear association. This improvement enriches the MMD files by directly linking equations with their corresponding numbers, facilitating easier reference and navigation.
Here is an example of how the result changes:
For this part of the PDF file
we currently return this MMD:
It is not immediately obvious from Maxwells equations that the time-varying current is the source of radiation. A simple transformation of the Maxwells equations
\[
\begin{aligned}
\nabla \times \mathbf{E} & =-\mu \frac{\partial \mathbf{H}}{\partial t} \\
\nabla \times \mathbf{H} & =\varepsilon \frac{\partial \mathbf{E}}{\partial t}+\mathbf{J}
\end{aligned}
\]
into a single second-order equation either for \(\mathbf{E}\) or for \(\mathbf{H}\) proves this statement. By taking the curl of both sides of the first equation in (1.2) and by making use of the second equation in (1.2), we obtain
\[
\nabla \times \nabla \times \mathbf{E}+\mu \varepsilon \frac{\partial^{2} \mathbf{E}}{\partial t^{2}}=-\mu \frac{\partial \mathbf{J}}{\partial t}
\]
From (1.3), it is obvious that the time derivative of the electric current is the source for the wave-like vector \(\mathbf{E}\).
With the new option enabled ("include_equation_tags": true), we now return:
It is not immediately obvious from Maxwells equations that the time-varying current is the source of radiation. A simple transformation of the Maxwells equations
\[
\begin{align*}
\nabla \times \mathbf{E} & =-\mu \frac{\partial \mathbf{H}}{\partial t} \tag{1.2a}\\
\nabla \times \mathbf{H} & =\varepsilon \frac{\partial \mathbf{E}}{\partial t}+\mathbf{J} \tag{1.2b}
\end{align*}
\]
into a single second-order equation either for \(\mathbf{E}\) or for \(\mathbf{H}\) proves this statement. By taking the curl of both sides of the first equation in (1.2) and by making use of the second equation in (1.2), we obtain
\[
\begin{equation*}
\nabla \times \nabla \times \mathbf{E}+\mu \varepsilon \frac{\partial^{2} \mathbf{E}}{\partial t^{2}}=-\mu \frac{\partial \mathbf{J}}{\partial t} \tag{1.3}
\end{equation*}
\]
From (1.3), it is obvious that the time derivative of the electric current is the source for the wave-like vector \(\mathbf{E}\).
Besides added equations numbers, there are other differences in the output:
Individual numbered equations are wrapped in \begin{equation*}...\end{equation*} to support numbering.
The aligned environment is now replaced with align* to support numbering
We also replace gathered with gather*.
In general, we will use the environments that support numbering when using "include_equation_tags": true.
These changes are also visible in lines.mmd.json format.
Here is what the rendering of the recognized portion of PDF page looks like:
Note that there are some limitations in the current implementation:
We do not generate equation references in the text (e.g. \ref{eq:1.3}). In the given example, in the last paragraph, the equation (1.3) is being referenced. While that reference is straight forward, equations (1.2a) and (1.2b) are being referenced as the first equation in (1.2) and the second equation in (1.2). This demonstrates that it takes significant semantic understanding of the document content to correctly unravel all the references, and is beyond the scope of this update.
We do not generate equation labels at the moment. The reasons are:
We do not generate \ref elements in text, and that would make \label elements redundant
Some widely used LaTeX rendering libraries do not support \label and \ref
When we have a block equation for which we output an array environment, and this block has multiple equation numbers associated with it, only the last equation number is being tagged. This is because LaTeX allows only one equation number per array. The same holds for the cases environment. We do plan to add support for the numcases environment which will enable multiple tags per one block of equations.
February 3, 2024
Deployed new ocr-version RSK-M127p2
Fixes internal error handling
February 3, 2024
Deployed new versions: RSK-M127p1, RSK-P111p1 (v3/pdf*)
Improvements to tabular outputs.
February 2, 2024
Deployed new versions: RSK-M127, RSK-P111 (v3/pdf*);
Initial OCR support Jordan matrices, improvements for tensor indices, and handwritten content;
For example, Mathpix can now correctly recognize matrices as this one:
\( W \upharpoonright N f\left(\frac{S}{N}, P\right) \)
December 7, 2023
Deployed new version (v3/pdf), RSK-P105;
Another improvement for table of contents pages.
November 28, 2023
Deployed new version (v3/pdf), RSK-P104;
Improved processing of table of contents pages.
October 31, 2023
Deployed new version (RSK-M120);
Chart detection;
This is a first step towards recognition of charts. Basic charts detection is supported in images.
When "include_line_data": true is specified in the request, for all the charts we now return correct chart type in line data response instead of generic diagram. Currently, several types of charts are being detected:
column chart
bar chart
line chart
pie chart
area chart
scatter chart
The type of chart is available as "subtype": ... field of the line object. This list will be extended with additional categories in the future.
Algorithm pseudo code recognition improvements.
We used to fail recognition for images with complex algorithm pseudocode like this one:
For such image, the returned MMD now looks like this:
Algorithm 1 Gradient Sign Dropout Layer (GradDrop Layer)
choose monotonic activation function \( f \quad \triangleright \) Usually just \( f(p)=p \)
choose input layer of activations \( A \quad \triangleright \) Usually the last shared layer
choose leak parameters \( \left\{\ell_{1}, \ldots, \ell_{n}\right\} \in[0,1] \quad \triangleright \) For pure GradDrop set all to 0
choose final loss functions \( L_{1}, \ldots, L_{n} \)
function \( \operatorname{BACKWARD}\left(A, L_{1}, \ldots, L_{n}\right) \quad \triangleright \) returns total gradient after GradDrop layer
for \( i \) in \( \{1, \ldots, n\} \) do
calculate \( G_{i}=\operatorname{sgn}(A) \circ \nabla_{A} L_{i} \quad \triangleright \operatorname{sgn}(\mathrm{A}) \) inspired by Equation 3
if \( G_{i} \) is batch separated then
\( G_{i} \leftarrow \sum_{\text {batchdim }} G_{i} \)
calculate \( \mathcal{P}=\frac{1}{2}\left(1+\frac{\sum_{i} G_{i}}{\sum_{i}\left|G_{i}\right|}\right) \quad \triangleright \mathcal{P} \) has the same shape as \( G_{1} \)
sample \( U \), a tensor with the same shape as \( \mathcal{P} \) and \( U[i, j, \ldots] \sim \operatorname{Uniform}(0,1) \)
for \( i \) in \( \{1, \ldots, n\} \) do
calculate \( \mathcal{M}_{i}=\mathcal{I}[f(\mathcal{P})>U] \circ \mathcal{I}\left[G_{i}>0\right]+\mathcal{I}[f(\mathcal{P})<U] \circ \mathcal{I}\left[G_{i}<0\right] \)
set newgrad \( =\sum_{i}\left(\ell_{i}+\left(1-\ell_{i}\right) * \mathcal{M}_{i}\right) \circ \nabla_{A} L_{i} \)
return newgrad
and it renders as:
While the correct indentation is still missing, the content is now being returned instead of Content not found error.
October 30, 2023
Deployed new version, RSK-P103p6 (v3/pdf*);
Added support for remove_section_numbering and preserve_section_numbering. Default behavior is changed
to preserve_section_numbering: True.
*Note that only one of auto_number_sections, remove_section_numbering, or preserve_section_numbering can be true at a time.
October 27, 2023
Deployed new versions: RSK-M119p7, RSK-P103p5 (v3/pdf*);
Post-processing improvements: we now return result instead of Internal error for some classes of challenging inputs.
October 21, 2023
Deployed new version, RSK-P103p3 (v3/pdf*);
Fixed new line inconsistencies that occurred when content from different pages is joined;
Single new line is generated before \footnotetext instead of two new lines;
Two new lines introduce a new paragraph, and that behavior was breaking rendering experience in some cases.
October 19, 2023
Deployed new version, RSK-M119p6;
False paragraph detection fixed for images with list items that start with Cyrillic letters.
October 18, 2023
Deployed new version, RSK-M119p5;
This update is focused towards more accurate separation of text into paragraphs.
October 14, 2023
Deployed new versions: RSK-M119p4, RSK-P103p2 (v3/pdf*);
Fixed whitespace between Chinese symbols which used to be generated when the adjacent text lines are joined.
Improved ordering of answers to multiple choice questions in some cases. For this part of PDF page:
we used to return the answers in height determined order:
10. Demostrar que si \(a, b \in \mathbb{R}\), entonces:
a) \(|-a|=|a|\).
e) \(|a-b| \leq|a|+|b|\)
b) \(\sqrt{a^{2}}=|a|\).
f) \(||a|-| b|| \leq|a-b|\).
c) \(|a-b|=|b-a|\).
g) \(a \neq 0,\left|\frac{1}{a}\right|=\frac{1}{|a|}\).
d) \(\left|a^{2}\right|=|a|^{2}\).
h) \(b \neq 0,\left|\frac{a}{b}\right|=\frac{|a|}{|b|}\).
Now, we return the answers in the correct order:
10. Demostrar que si \(a, b \in \mathbb{R}\), entonces:
a) \(|-a|=|a|\).
b) \(\sqrt{a^{2}}=|a|\).
c) \(|a-b|=|b-a|\).
d) \(\left|a^{2}\right|=|a|^{2}\).
e) \(|a-b| \leq|a|+|b|\)
f) \(||a|-| b|| \leq|a-b|\).
g) \(a \neq 0,\left|\frac{1}{a}\right|=\frac{1}{|a|}\).
h) \(b \neq 0,\left|\frac{a}{b}\right|=\frac{|a|}{|b|}\).
October 12, 2023
Deployed new version, RSK-M119p3;
Accuracy improvements of Korean and handwritten Chinese;
Fixes several issues with braces recognition.
Here is an example image:
Result before (missing outer braces):
Result with current version:
October 9, 2023
Deployed new version (v3/pdf*), RSK-P103;
more reliable recognition of footnote text;
initial support for table of contents;
pseudo code algorithms are now searchable;
individual lines from pseudo code algorithms will be a part of lines.json output.
September 5, 2023
Deployed new version (v3/pdf*), RSK-P101;
Added basic support for text in the footnote section of the page. Instead of breaking the main flow, especially in multi-column documents, the text will be wrapped inside \footnotetext{ ... }.
May 25, 2023
Deployed new version, RSK-115;
Improved quality of printed and handwritten Chinese recognition.
April 12, 2023
Deployed new version, RSK-113;
This update is focused on chemistry recognition.
As a reminder, when "include_smiles": true is a part of the request, Mathpix can recognize chemistry diagrams such as:
and return the SMILES representation which looks like this:
<smiles>Cn1c(=O)c2c(ncn2C)n(C)c1=O</smiles>
The list of improvements:
support for stereochemistry:
for example, the image
is transcribed to: <smiles>O=S(=O)(c1ccc(F)cc1)N1C[C@@H](O)[C@H](N2CCCC2)C1</smiles>;
support for Markush structures:
for example, the image
is transcribed to <smiles>[Z2]Nc1c(CC([R10])CSC)ncn1CC#C</smiles>;
basic support for superatoms:
more superatoms will be supported in future;
significant recognition accuracy improvement for both handwritten and printed chemistry diagrams.
February 22, 2023
Deployed new version, RSK-111;
Added support for the new table recognition algorithm;
Minor general changes needed to properly support the algorithm.
A new table recognition algorithm is available in the v3/text and v3/pdf endpoints. It can be enabled by specifying "enable_tables_fallback": true as one of the request arguments.
We care deeply about backwards compatibility. The new algorithm will only be used if both of the following conditions are fulfilled:
Our standard algorithm failed to recognize a table;
"enable_tables_fallback": true is specified as a request argument.
We have ensured that there will be no computational overhead for customers who do not specify this option, so response times will not be affected.
We have invested in a hybrid approach that will be able to tackle complicated cases like:
extremely large tables (e.g. tables with hundreds of cells);
tables with very complex structures (e.g. tables with many \multirow and \multicolumn cells);
tables featuring table cells with complex content like:
table cells with complex math like large matrices or several aligned equations;
tables cells containing whole paragraphs of text;
tables containing text in languages that are more challenging to recognize properly compared to English:
this includes languages with rich alphabets like Chinese, Japanese, Hindi, Hebrew, Arabic, and others;
tables containing cells with rotated text;
tables containing diagrams inside cells like:
table cells with chemistry diagrams (note that these can be converted to SMILES);
table cells with natural images or similar:
table will still be recognized and contain the image link for the diagram inside its cells.
We will also support all combinations of the above cases.
The algorithm we are releasing now might still struggle with:
tables with cells containing complex math like large matrices or several aligned equations;
tables containing diagrams inside cells;
empty grids of cells without textual content;
tables with rotated text are partially supported:
in v3/pdf cells containing rotated text will be embedded as images.
We will add improvements that will cover specified cases shortly.
Some differences in output produced by the new algorithm compared to the standard one:
Column alignment is always central;
All cells have all borders (top, bottom, right, and left).
February 1, 2023
Deployed new version, RSK-110;
Added support for new LaTeX commands: \measuredangle, \grave, \bumpeq, and \amalg;
Improved recognition of constructs expressed with \lceil, \rceil, \lfloor, and \rfloor in combination with \left and \right;
Improved formatting of equations in text mode (see bellow for details);
Improved recognition of equations that contain large sub-equations in subscripts;
Improved recognition of handwritten French;
Improved recognition of handwritten German;
Improved recognition of handwritten Chinese;
Improved recognition of handwritten Japanese;
General improvements (new data iteration).
The default “text” output has been changed, for example see the following equation:
from the current “text” output:
\( y=mx+b \)\n\( x=y^{2}-1 \)
and two asciimath equation outputs, to:
\( \begin{array}{l} y = mx + b \\ x=y^{2}-1 \end{array} \)
with one single asciimath equation output:
{:[y=mx+b],[x=y^(2)-1]:}
which will make the “text” derived formats more consistent with what is currently returned for equations with a left brace:
Since we are already emitting in certain cases (eg, equations with no braces aligned around the “=” sign instead of being left aligned) asciimath for v3/text that looks like:
{:[2x+8y=21],[6x-4y=14]:}
we consider this update to be an inconsistency bugfix instead of a new feature with the potential to break backwards compatibility.
In general, it is desirable for our API for small changes in input to result in small changes in output. For example, removing the left brace from equation 2 will simply change the v3/text asciimath from:
{[2x+8y=21],[6x-4y=14]:}
to:
{:[2x+8y=21],[6x-4y=14]:}
which is a smaller change than the previous behavior, in which subtracting a left brace results in two equations instead of 1.
January 30, 2023
Deployed new version, RSK-109;
Improved recognition of isolated symbols.
January 12, 2023
Deployed new version, RSK-108;
Improved handling of images that contain mixed math and text in Russian.
December 2, 2022
Deployed new version, RSK-107p2;
Changes in spacing of arrays, aligned arrays and similar, & and \\ now always have spaces around them (even with rm_spaces in the request);
Visually unpleasant blocks of equations are being converted to left alignment instead of keeping the wrong alignment.
November 25, 2022
Deployed new version, RSK-107;
Improvements related to worksheet crops, small images with strong or dashed border near the content.
November 22, 2022
Deployed new version, RSK-106;
Improvements related to formatting of references in PDF pages, especially pages with green/red link boxes.
November 15, 2022
Deployed new version, RSK-105;
General improvements to handling zoomed out and zoomed in images. No changes to output formatting or error characteristics.
November 14, 2022
Deployed new version RSK-104p1;
Formating of block math is fixed in certain cases where the equations were wrongly kept in the text mode.
November 11, 2022
Deployed new version RSK-104;
Incremental improvement of image parsing module. Includes fixes for images with many lines of text. Accuracy improvements on handwritten data. No changes to output formatting.
November 3, 2022
Deployed new version RSK-103p1;
Fixed string post processing issues.
In this version, we have changed the default Markdown / LaTeX for the following character:
# -> \#
While # works fine in Markdown and has the same behavior as \#, the former causes LaTeX compilation issues, whereas \# succeeds in LaTeX without any problem. We chose to always emit LaTeX \# instead of # so that our output would be more compatible and less likely to cause issues. The updated character \# is compatible with Markdown as well as LaTeX.
Unescaped # will simply no longer appear in OCR Markdown / LaTeX outputs.
Alternative math formats such as Asciimath are not affected by the change, this is a Markdown / LaTeX change only.
October 21, 2022
New enable_spell_check option to the v3/text and v3/pdfs endpoints greatly improves handwriting OCR for English (other languages coming soon).
June 6, 2022
Resolved a critical bug that impacted PDF processing of two-column PDFs;
You can now request that only certain subsets of pages are processed in a PDF, via the new page_ranges field;
Pushed latency improvements that benefit all endpoints, reducing processing time by 30% on average;
Updated how line data is represented for PDFs from using rectangular regions to polygonal contours (this is helpful for handwritten PDFs where text lines are generally not rectangular);
Added page dimensions to the line-by-line data structures;
There are two available data structures for line-by-line data:
Raw PDF lines data: this is the ideal data structure for searching; does not contain contextual annotations for titles, abstracts, etc;
Context enhanced PDF mmd lines data: you can use this to re-create the full document, including contextual annotations for titles, abstracts, etc. (see here for syntax);
Published a Github repo which contains client-side code for live
drawing with the Mathpix digital ink API containing a fully working example of leveraging user actions like scribbling
and strikethrough to delete content.
April 18, 2022
Added an EU server region (AWS region eu-central-1) to decrease latencies for European customer and also for adherance to GDPR:
You can now use app-tokens for authenticating requests inside client side app code;
The new app-tokens route provides a include_strokes_session_id flag, which when true, returns a strokes_session_id string that can be used inside calls to v3/strokes, enabling digital ink sessions with live updates:
Pricing for the strokes endpoint when using session_ids can be found here;
Add OCR support for basic handwritten PDFs.
March 28, 2022
You can now get detailed line-by-line data for PDFs, including geometric coordinates, via the new GET v3/pdf/<pdf_id>.lines.json endpoint;
Better robustness for our v3/text endpoint:
Our ability to correctly interpret complex layouts involving math and text has improved, with much-improved edge case handling and handling of line text for skewed images and other image distortions that occur frequently in consumer photo search applications.
March 14, 2022
Our new OCR models feature stringent guarantees of syntactic correctness, resolving a rare but long-standing problem of occasionally malformed LaTeX strings, resulting in rendering errors due to double subscripts, double superscripts, malformed tables, and other syntax issues. This has been fixed at a fundamental level. Syntax issues are essentially completely fixed;
Deprecated \atop command in favor of \substack.
February 8, 2022
We have recently switched to a new, faster database to save image and PDF data. Next week, we will decommission our old database. This will result in OCR API image results log data from before December 1st, 2021 becoming unavailable via the GET v3/ocr-results endpoint. Note that we have already migrated all PDF data to the new database, so there will be no data loss for PDF data.
November 15, 2021
Deployed incremental update to our re OCR engine, resulting in:
significantly improved handwriting recognition, including disambiguating symbols based on context;
improved table parsing accuracy;
notably fewer errors.
September 2, 2021
Deployed a core algorithm update for our image parsing module, resulting in significantly better accuracy and edge case behavior for all endpoints;
Added support for Tamil, Telugu, Gujarati, and Bengali;
Updated our OCR to use a more effective representation of Chinese characters, leading to higher accuracy, and better coverage;
Added support for \bigcirc.
July 19, 2021
Support for sending image binaries for lower image upload latencies;
Support for tags which allow you to associate an attribute with your requests and subsequently retrieve the associated requests by using tags in a /v3/ocr-results query;
PDF processing updates:
Fixed a bug where pages were getting skipped;
Improved processing of PDFs with foreign languages;
Servers in Singapore for faster latencies for API customers in Asia;
Triangle diagram OCR now supported for diagrams commonly found in trigonometry textbooks;
Added InChI option for chemical diagram OCR.
April 2, 2021
Added a include_word_data parameter to the v3/text endpoint, which when set to true, returns word by word information, with separate results, confidences values, and contour coordinates for each word;
Significant accuracy improvements to text / math localization performance for v3/latex and v3/batch for both ocr=["math"] (default) as well as ocr=["math", "text"], resulting in lower error rates and fewer bad results.
November 12, 2020
Added autorotation for v3/text.
Images like this now work in v3/text:
The goal of automatic rotation is to pick correct orientation for received images before any processing is done. The result of auto rotation looks like:
We will soon add these features to v3/latex and v3/batch as well. We implemented a very conservative rotation confidence threshold, meaning you should still try to call the API with a properly oriented image if possible!
First of all, we trained our models on a larger dataset, resulting in a general accuracy increase.
Secondly, we improved the precision of predictions, at the potential cost of slightly decreasing prediction recall in some circumstances. Here is an example of an image, where previously our v3/text tried to read the bottom, cut off parts of the image:
Now, v3/text ignores these sections, resulting in a much cleaner output than before. The endpoint will still try to read everything in an image (vs the v3/latex endpoint which tries to read the main equation), but will be slightly less aggressive in reading unusual image sections in order to avoid garbage outputs.
Chemistry diagram detection;
We have added a new field in our LineData object, subtype, so that we can return more information about diagrams to API clients. Currently subtype can only be chemistry, but more diagram subtypes are coming soon.