Processing PDFs with Mathpix Python SDK
The Mathpix Python SDK allows you to process entire PDF files and extract content such as text, LaTeX, Mathpix Markdown (MMD), and more.
Code Example
from mpxpy.mathpix_client import MathpixClient
client = MathpixClient(
app_id="your-app-id",
app_key="your-app-key"
)
# Process a PDF with multiple output formats
pdf = client.pdf_new(
url="https://cdn.mathpix.com/examples/cs229-notes1.pdf",
convert_to_md=True,
convert_to_docx=True,
)
# Wait for processing to complete. Optional timeout argument is 60 seconds by default.
pdf.wait_until_complete(timeout=60)
# Get the Markdown outputs
md_output_path = pdf.to_md_file(path='output/sample.md')
md_text = pdf.to_md_text() # is type str
print(md_text)
# Get the DOCX outputs
docx_output_path = pdf.to_docx_file(path='output/sample.docx')
docx_bytes = pdf.to_docx_bytes() # is type bytes
# Get the JSON outputs
lines_json_output_path = pdf.to_lines_json_file(path='output/sample.lines.json')
lines_json = pdf.to_lines_json() # parses JSON into type Dict
Visual Example: From PDF to Markdown
This example shows how the Mathpix Python SDK can process a PDF and convert its content into structured Markdown with math formatting.
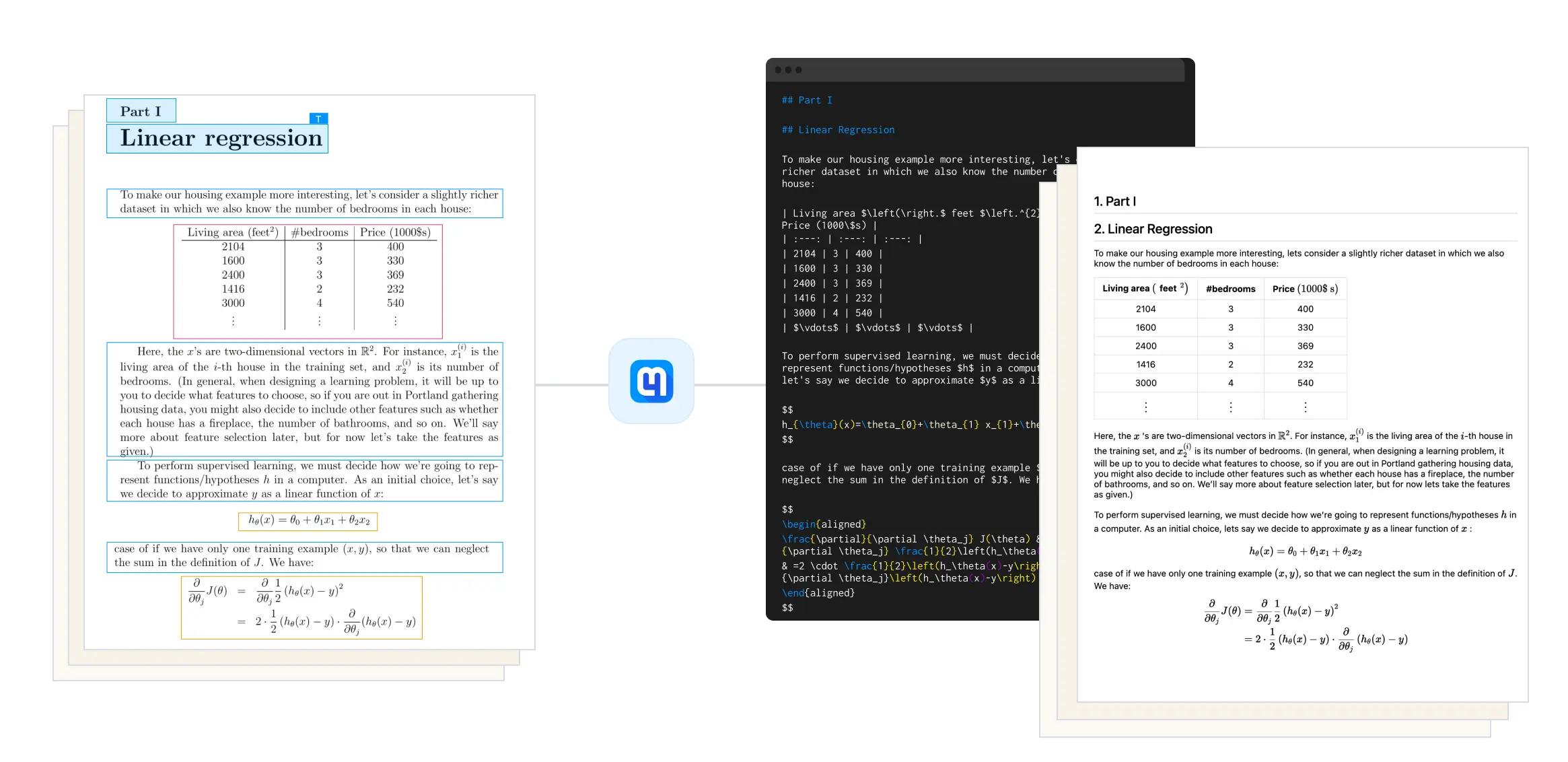
The converted result includes structured text, LaTeX math, and tables extracted from the original document.
- Use
to_*methods to either get the result in memory or save it directly to a file. - Saving to file always requires setting the
pathexplicitly — the SDK will not guess or generate filenames automatically. - All folders in the provided
pathare created automatically if they do not exist. - If you only need in-memory content (e.g. for sending over a network or writing to a DB), use the
to_*_bytes()orto_*_text()methods.
Output Formats
- Markdown
Saved to:output/sample.md
Also returned as a string viapdf.to_md_text().
- DOCX
Saved to:output/sample.docx
Also available in-memory usingpdf.to_docx_bytes()— useful for returning as a file in web apps.
- Line-by-line JSON
Saved to:output/sample.lines.json
Parsed in-memory usingpdf.to_lines_json()— includes per-line OCR with math, text, bounding boxes, and handwriting detection.
Other formats such as HTML, LaTeX ZIP, and rendered PDF are also supported — see full method list below.
Pdf Class Documentation
Properties
auth: An Auth instance with Mathpix credentials.pdf_id: The unique identifier for this PDF.file_path: Path to a local PDF file.url: URL of a remote PDF file.convert_to_docx: Optional boolean to automatically convert your result to DOCX.convert_to_md: Optional boolean to automatically convert your result to Markdown.convert_to_mmd: Optional boolean to automatically convert your result to Mathpix Markdown.convert_to_tex_zip: Optional boolean to convert result to LaTeX ZIP archive.convert_to_html: Optional boolean to convert result to HTML.convert_to_pdf: Optional boolean to re-render result to PDF.
Methods
-
wait_until_complete(): Wait until the PDF has been fully processed. -
pdf_status(): Return the current processing status. -
pdf_conversion_status(): Return the current conversion status. -
to_docx_file(path): Save the DOCX output to a local file. -
to_docx_bytes(): Get the DOCX output as bytes. -
to_md_file(path): Save the Markdown output to a local file. -
to_md_text(): Get the Markdown output as a string. -
to_mmd_file(path): Save Mathpix Markdown to a local file. -
to_mmd_text(): Get Mathpix Markdown as a string. -
to_tex_zip_file(path): Save LaTeX ZIP output to a file. -
to_tex_zip_bytes(): Get LaTeX ZIP output as bytes. -
to_html_file(path): Save HTML output to a file. -
to_html_bytes(): Get HTML output as bytes. -
to_pdf_file(path): Save re-rendered PDF to file. -
to_pdf_bytes(): Get PDF as bytes. -
to_lines_json_file(path): Save line-level OCR as a JSON file. -
to_lines_json(): Get line-level OCR data as Python dict. -
to_lines_mmd_json_file(path): Save line-level OCR (in MMD) as JSON file. -
to_lines_mmd_json(): Get line-level OCR (MMD format) as dict.